
简介
作者将卷积神经网络的高层激励输出称为neural codes,文章的主要工作就是评测了neural codes作为图像全局描述子时用于图像检索的性能。
pre-trained neural codes
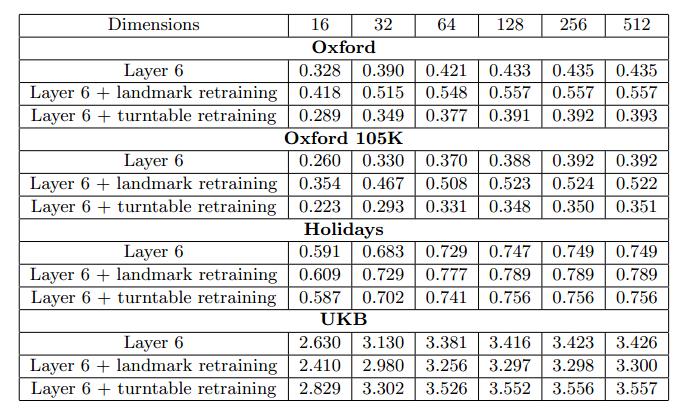
作者首先利用12年经典的deep-CNN在ImageNet上训练好的模型进行实验。在Oxford、Oxford 105K、Holidays、UKB这四个数据集上的结果表明,预先训练好的neural codes已经可以得到较好的性能,但并没有超过目前state-of-art的人工特征如Fisher。另外作者也发现效果最好的特征不是较高层的L7层输出而是L6层。
retrained neural codes
由于ImageNet数据集与检索数据集有一定差异,因此一个直观的想法就是针对检索数据集对模型重新训练以提高性能。因此作者重新收集共有672个类别的land mark数据,使用和ImageNet相同的模型结构并用ImageNet的参数初始化完成训练。实验结果表明利用重新训练的模型提取出的neural codes确实可以得到更好地效果,在前三个数据集上的效果有所提升,并且在Holidays数据集上得到了目前为止最好的效果,但UKB数据集的效果反而下降。作者认为这是由于UKB数据集与用于重训练的数据集差异较大,不如与ImageNet某几个类别下的数据相似性高。

降维
对于大规模图像检索来说,只有较低维度的特征才在实际应用中有意义,而CNN的激励输出和几种人工特征的维数都高达几千维,因此必须进行降维。作者利用PCA对这几种特征降维发现,虽然重训练后的neural codes相对人工特征并没有太多优越性,但PCA降维后的neural codes在三个数据集上都得到了比同维度的人工特征更好的结果。另外作者也提出用匹配图像进行判别式降维,相对PCA效果更好。
想法
这篇paper从理论上并没有什么创新的地方,不过与我们的实际应用很贴近。启发和问题如下:
neural codes的PCA降维对性能损失影响很小,而128维的特征已可用于实际系统。 通过深度学习提取的特征性能并没有预想的好,只是和人工特征相近,在降维后才体现出一定优势。 有必要对模型进行重训练。因为作者提到训练数据集和检索数据集的相似性对检索效果有影响,而ImageNet可能包含较少的目标类型图像,如何重训练数据集有较多标记正确的数据,相信会对结果有较大提高。
- 重训练数据集如何构建很重要。对于京东数据而言,类别的确定应该更加fine-grained,如果粗糙的按鞋、包、电视这样分类训练,在特定品类下的检索一定效果不佳。比如对于衣服品类下的搜索而言,我认为可以先根据文本确定出精细的类别,这样才可以训练出对不同类型衣服如短裙、上衣、衬衫有不同响应级别的unit,否则训练出的unit区分性差。
- 文章中的重训练数据集与检索数据集不同,如果在检索数据上进行训练,是否会提升效果?